




En juillet 2025, OpenAI a participé aux Olympiades internationales de mathématiques et a remporté la médaille d'or. Ils y sont parvenus non pas en mémorisant des problèmes antérieurs, mais en raisonnant étape par étape, comme des concurrents humains.
Un mois plus tard, l'OpenAI a participé à l'Olympiade internationale d'informatique (IOI), un concours de codage analogue, et a de nouveau décroché l'or. Et ils ont gagné avec le même modèle. Alexander Wei, responsable du raisonnement chez OpenAI, a résumé cette avancée en deux mots : "Le raisonnement se généralise !"
L'intelligence artificielle connaît un changement de paradigme fondamental. Au cours de la dernière décennie, les systèmes d'IA ont évolué de l'IA analytique (modèles analysant des données structurées avec des résultats déterministes) à l'IA générative (modèles d'apprentissage profond capables de produire des résultats non structurés tels que du texte et des images). Aujourd'hui, nous assistons à l'émergence d'une nouvelle frontière : L'IA raisonnante, des agents à la recherche d'objectifs qui peuvent penser de manière itérative, corriger leurs propres erreurs et gérer des tâches à long terme.
Cette nouvelle génération combine des modèles de base auto-supervisés avec l' apprentissage par renforcement (RL) et des calculs massifs en temps réel, ce qui permet à l'IA d'aller au-delà de la reconnaissance des formes et de passer à une véritable inférence et à une véritable adaptation. Ces systèmes vont au-delà de la prédictiondu prochain mouvement et planifient activement plusieurs mouvements à l'avance, en ajustant continuellement leur approche pour atteindre un objectif défini.
Nous considérons que la montée en puissance de l'IA de raisonnement en tant que niveau de capacité distinct constitue un point d'inflexion clé sur le marché. Les emplois et les tâches que l'on pensait jusqu'à présent "inautomatisables" ou "hors de portée de ce que l'IA peut faire" sont désormais à notre portée. Prenons l'exemple d'un cas médical difficile à diagnostiquer ou de la préparation d'une déclaration d'impôts complexe ; nous pouvons désormais envisager un avenir proche dans lequel des tâches qui ne sont pas bien représentées dans les données d'apprentissage ou qui sont même totalement nouvelles pourront être accomplies par l'IA de raisonnement. Les idées reçues telles que "il y aura toujours une partie de ce travail qui ne pourra être effectuée que par un humain" doivent être repensées. L'IA raisonnée a des implications sur la manière d'aborder la décision de conception d'un produit entre l'assistance humaine et l'automatisation complète, et elle ouvre de nouvelles opportunités de marché pour les fondateurs.
Cet essai examine les mécanismes qui sous-tendent ce changement, présente des preuves empiriques provenant de nouveaux critères, explore les implications dans le monde réel au moyen d'études de cas détaillées et explique comment la nouvelle génération d'entreprises d'IA de raisonnement sera loin d'être des "enveloppes LLM".
Raisonner l'IA : une nouvelle frontière de capacités
Tout comme le passage du logiciel traditionnel à l'apprentissage automatique a introduit l'IA analytique, et l'évolution des réseaux neuronaux profonds sur les données non structurées a produit l'IA générative, l'essor de l'IA de raisonnement marque une nouvelle frontière de capacité. Chaque époque a élargi le champ des tâches que les machines peuvent accomplir :
IA analytique (avant 2015) : Ces systèmes se concentrent sur les données structurées et la prédiction statique. Pensez aux modèles de régression ou aux arbres de décision dans les bases de données. Ils excellaient dans des tâches étroites et bien définies telles que l'évaluation du crédit, l'optimisation de la chaîne d'approvisionnement ou la détection d'anomalies. L'IA analytique s'est avérée puissante dans des domaines restreints, mais elle est restée fondamentalement limitée à la mise en correspondance des entrées et des sorties sur la base de modèles dans des données historiques structurées. Il manquait de créativité et ne pouvait pas être généralisé au-delà de la distribution de la formation.
L'IA générative (2016-2023) : Cette ère, catalysée par l'apprentissage profond à grande échelle, a apporté des modèles qui ingèrent des données non structurées (texte, images, audio) et génèrent de nouveaux contenus. Des systèmes tels que GPT-3 et DALL-E ont été formés par apprentissage auto-supervisé sur des corpus à l'échelle de l'internet, ce qui leur permet de synthétiser du texte et des images avec une fluidité remarquable. L'IA générative a fait preuve d'une créativité impressionnante et d'une grande ouverture, mais ces modèles restent fondamentalement des imitateurs demodèles: ils prédisent des suites ou des achèvementsprobables sur la base de données d'apprentissage. Ils n'ont pas de notion explicite d'objectifs ou de planification en plusieurs étapes. Un modèle de langage génératif peut produire un essai ou un extrait de code plausible en une seule fois, mais il ne planifiera pas de stratégie de solution ou ne corrigera pas lui-même ses erreurs à moins d'y être explicitement invité.
L'IA raisonnante (2024+) : Ce paradigme émergent s'appuie sur les modèles génératifs, mais y ajoute la délibération et la pensée orientée vers un objectif. Les systèmes d'IA de raisonnement s'appuient sur de grands modèles auto-supervisés (qui fournissent des connaissances générales et une reconnaissance des formes), puis les affinent grâce à l'apprentissage par renforcement pour des objectifs spécifiques et, surtout, permettent un calcul itératif au moment de l'inférence. Au lieu d'une prédiction unique, le modèle s'engage dans un processus de raisonnement en plusieurs étapes : il génère des étapes intermédiaires, vérifie les résultats et affine son approche. Cette intégration de la planification à long terme et du retour d'information permet à l'IA raisonnante de s'attaquer à des problèmes nécessitant une séquence de déductions ou d'actions logiques, là où la simple imitation des données d'apprentissage ne suffirait pas. Un agent IA de raisonnement confronté à une nouvelle tâche peut simuler en interne un processus de réflexion, en explorant différents chemins de solution et en revenant en arrière si nécessaire, à l'instar d'un raisonneur humain.
Ce changement au raisonnement L'IA est un changement radical de capacité. Les modèles de raisonnement formés par RL sont nettement plus performants que les modèles génératifs standard. Les grands modèles linguistiques optimisés uniquement par l'apprentissage auto-supervisé (SSL) plafonnent pour des tâches telles que les mathématiques complexes ou la synthèse de codes. L'ajout d'une couche d'entraînement polyvalent à la NR permet d'atteindre de nouveaux sommets en matière de performances. Les meilleurs laboratoires de recherche se sont orientés vers la formation de modèles de raisonnement à usage général plutôt que vers la formation de modèles spécifiques à une tâche. Ces agents ne sont pas conçus pour jouer à un seul jeu ou suivre des instructions simples, mais pour résoudre des problèmes mathématiques complexes, écrire un code correct, dériver des preuves formelles, faire fonctionner un ordinateur et bien d'autres choses encore, ce qui leur permet de remporter des succès remarquables. Si l'IA générative concernait la synthèse non structurée, l'IA de raisonnement concerne la résolution structurée de problèmes. Elle cherche à atteindre des objectifs dans des environnements ouverts, en élaborant et en exécutant des plans plutôt qu'en produisant des réponses ponctuelles.
Les implications sont profondes. L'IA analytique a largement automatisé le calcul et la prédiction sur des données propres. L'IA générative a automatisé la création de contenu et fourni des interfaces fluides comme les assistants conversationnels et la génération d'images. L'IA de raisonnement a le potentiel d'automatiser les flux de travail cognitifs - les tâches multi-étapes, chargées de décisions, que seuls les experts pouvaient effectuer auparavant. Il s'agit notamment de domaines "très complexes et difficiles à vérifier", où le succès ne consiste pas seulement à produire quelque chose qui semble correct, mais à suivre un long processus qui peut facilement échouer à de nombreux stades. Pensez au débogage de logiciels complexes, au diagnostic d'une maladie à partir de ses symptômes, à la rédaction et à la négociation de contrats juridiques ou à la préparation des déclarations fiscales des entreprises. Ces processus impliquent une planification, une réaction aux nouvelles informations et une vérification continue des erreurs. Jusqu'à présent, ces flux de travail étaient considérés comme dépassant largement le cadre de l'IA. Avec Reasoning AI, les choses changent rapidement.
Deux leviers qui ont tout changé : RL + Test-Time Compute
Au cœur de l'IA raisonnante se trouve le concept selon lequel un modèle d'IA peut délibérer. Plutôt que de passer directement de l'entrée à la sortie en une seule étape, un agent de raisonnement effectue une séquence d'opérations internes - des étapes de réflexion communément appelées "chaîne de pensée" (CoT) - avant de finaliser un résultat. Cette capacité découle de deux innovations essentielles : la possibilité d'augmenter considérablement les calculs au moment de l'inférence et l'apprentissage par renforcement du modèle afin qu'il développe des stratégies internes utiles (telles que la planification, l'utilisation de la mémoire et la correction des erreurs) que les êtres humains utilisent généralement pour élaborer des solutions.
Raisonnement itératif via le calcul du temps de test
Les modèles d'IA traditionnellement déployés ont été "fixés" au niveau de l'inférence ; ils font passer les entrées par le réseau neuronal une fois et produisent une réponse. Si la réponse est erronée, il n'y a pas de seconde chance, à moins que vous n'entraîniez à nouveau le modèle ou que vous ne l'incitiez à nouveau à partir de zéro. Le calcul en temps réel change ce paradigme en donnant aux modèles la possibilité de "penser". Dans la pratique, cela signifie qu'il faut exécuter le modèle pour plusieurs passages avant, générer des CoT intermédiaires, explorer de nombreuses réponses candidates en parallèle ou utiliser davantage de calculs par requête qu'un passage unique standard. Nous pouvons échanger des calculs supplémentaires contre une meilleure précision à la volée.
Plusieurs formes de ce "temps de réflexion" existent dans les systèmes actuels. L'invite CoT demande au modèle de générer une trace de raisonnement étape par étape avant d'arriver à une conclusion. Le vote à la majorité ou l'échantillonnage des meilleures réponses possibles génère de nombreuses réponses possibles et sélectionne la plus courante ou la mieux notée. Des approches plus sophistiquées, telles que l'arbre de pensée, permettent au modèle d'emprunter plusieurs voies de raisonnement, d'évaluer des solutions partielles et de revenir en arrière ou de poursuivre des voies prometteuses. Toutes ces techniques ont en commun le principe de l'affinage itératif.
De manière empirique, le calcul en temps réel s'est avéré immensément puissant. Les chercheurs de l'OpenAI notent que leurs nouveaux modèles s'améliorent nettement avec l'augmentation du temps de réflexion (test-time compute), même sans changer les poids du modèle. Lorsqu'ils s'attaquent à des problèmes de codage complexes, les modèles de raisonnement modernes ne se contentent pas d'essayer une seule solution.Ils génèrent des dizaines de programmes candidats, les testent par rapport à des casunitaires et les affinent.
Le résultat o3 de l'OpenAI sur le benchmark Abstraction and Reasoning Corpus (ARC) constitue une étude de cas spectaculaire. L'ARC a été conçu comme un test d'intelligence générale, facile pour les humains et extrêmement difficile pour l'IA, où la reconnaissance pure des formes échoue. Les modèles génératifs antérieurs ont obtenu un score proche de 0%. Le modèle "o3" d'OpenAI a fait une percée : avec un budget de calcul standard, il a obtenu un score d'environ 75% sur l'évaluation ARC - et lorsqu'il a été autorisé à fonctionner avec un budget de calcul 172 fois plus élevé (des milliers de solutions parallèles explorées pendant 10 minutes), il a atteint 87,5%, dépassant le seuil de niveau humain. Le résultat a été une "augmentation par étapes" de la capacité, révélant "une nouvelle capacité d'adaptation à la tâche jamais vue auparavant dans les modèles de la famille GPT". En investissant plus de temps de réflexion dans le problème, l'IA a atteint un niveau qualitativement plus élevé de résolution de problèmes. Les résultats de l'ARC ont démontré que "les performances sur les nouvelles tâches s'améliorent avec l'augmentation de la puissance de calcul", mais qu'il ne s'agissait pas d'une simple force brute, mais que cela nécessitait la nouvelle architecture du modèle. Cela souligne la façon dont l'inférence itérative a ouvert un nouvel axe d'amélioration, orthogonal à la simple mise à l'échelle de la taille du modèle ou de la taille de l'ensemble de données. François Chollet, qui a créé le test ARC, a écrit que "toutes les intuitions concernant les capacités de l'IA devront être mises à jour pour o3".
Les chercheurs explorent les moyens permettant aux modèles d'IA d'apprendre et de s'améliorer au cours de l'inférence, et pas seulement lors de l'entraînement hors ligne. L'apprentissage par renforcement en fonction du temps (TTRL), introduit par Zuo et al, est l'une de ces méthodes. Il traite chaque nouvelle question comme un mini-environnement d'apprentissage, dans lequel le modèle génère plusieurs réponses et utilise l'accord entre elles comme un signal de ce qui est probablement correct. Si la plupart des réponses sont d'accord, ce consensus est traité comme une récompense, ce qui permet au modèle de renforcer les modèles qui y ont conduit. Il est surprenant de constater que cette approche permet au modèle de s'améliorer au-delà de ses capacités initiales, même en l'absence de données de formation étiquetées. Dans certains cas, TTRL est presque aussi performant que les modèles formés directement sur l'ensemble de test avec de vraies réponses. Bien que la recherche en soit encore à ses débuts, le TTRL laisse entrevoir des systèmes d'IA capables de s'adapter et d'évoluer en temps réel, simplement en interagissant avec de nouveaux problèmes.
Le calcul en temps réel permet à l'IA de résoudre activement les problèmes. Plutôt que d'être limités à une seule passe, les modèles peuvent désormais simuler des processus de pensée d'une longueur arbitraire, limitée uniquement par la puissance de calcul disponible. Cela permet un raisonnement à long terme: le modèle peut s'attaquer à des tâches nécessitant des dizaines de calculs ou de décisions intermédiaires en allouant du temps de calcul pour les parcourir. Les modèles génératifs "statiques" de ces dernières années répondaient instantanément, mais parfois de manière impulsive et incorrecte. La nouvelle approche ressemble à un penseur diligent qui prend son temps, réfléchit, vérifie deux fois et peut recommencer si nécessaire.
Optimisation dirigée par les objectifs avec apprentissage renforcé
Un temps de réflexion plus important serait gaspillé si les modèles ne savaient pas comment l'utiliser de manière productive. L'apprentissage par renforcement permet de résoudre ce problème en formant les systèmes d'intelligence artificielle à l'aide de signaux de récompense explicites lorsqu'ils atteignent leurs objectifs, ce qui leur confère une certaine intentionnalité - une volonté de comprendre les choses correctement, plutôt que de se contenter d'imiter des résultats plausibles. L'apprentissage par renforcement transforme un modèle prédictif passif en un agent actif qui tente d'accomplir quelque chose. "Le paradigme" de James Betker, chercheur à l'OpenAI, est une excellente introduction à ce sujet.
Lorsque nous optimisons un modèle avec RL, nous ne lui demandons plus de modéliser la distribution de probabilité d'un ensemble de données. Au lieu de cela, nous définissons une fonction de récompense pour le comportement souhaité et laissons le modèle explorer des séquences d'actions (ou des générations de jetons) qui donnent lieu à une récompense élevée. Chaque séquence de pensées et de sorties du modèle peut être considérée comme une trajectoire dans un environnement. Le processus d'apprentissage RL ajuste le modèle pour produire des trajectoires qui obtiennent de bons résultats. Le modèle apprend une politique : une correspondance entre les états (le contexte actuel ou la solution partielle) et les actions suivantes (le prochain jeton ou la prochaine décision) qui tendent à atteindre l'objectif.
Un effet immédiat : le modèle développe des sous-programmes utiles - des stratégies intériorisées pour gérer des situations récurrentes lors de la résolution de tâches. Tout comme les humains apprennent inconsciemment des compétences qui peuvent être combinées (la conduite implique des sous-programmes tels que changer de vitesse, vérifier les rétroviseurs, appuyer sur les pédales), un grand modèle de langage peut apprendre des sous-programmes de raisonnement allant de "c'est un problème difficile et je devrais réfléchir davantage" à des schémas de programmation courants. Ces compétences apparaissent parce qu'elles contribuent à l'obtention d'une récompense. Les modèles de raisonnement entraînés par RL présentent des comportements distinctifs tels que des calculs à l'aide d'un bloc-notes, des déductions logiques étape par étape et des phrases d'autocontrôle. Ils acquièrent des compétences modulaires qui peuvent être enchaînées pour atteindre des objectifs.
La correction des erreurs est peut-être la compétence émergente qui a le plus d'impact. Les modèles linguistiques standard formés uniquement par apprentissage de la vraisemblance ne disposent d'aucun mécanisme pour se corriger véritablement lorsqu'ils s'écartent de la bonne voie. On ne leur a jamais enseigné explicitement ce qu'il faut faire en cas d'erreur. Si un modèle génératif produit une séquence de jetons non plausible, il ne dispose pas d'un moteur intégré pour revenir sur la bonne voie. RL change cela. En ne récompensant que les résultats positifs (et peut-être quelques étapes intermédiaires), le modèle apprend à identifier ses dérives et à prendre des mesures correctives. Les modèles de raisonnement polyvalents formés à l'aide du RL font souvent preuve d'un comportement de remise en question, en utilisant des mots tels que "mais", "sauf" ou "peut-être" lorsqu'ils détectent des erreurs potentielles et révisent leur approche. Cette autocorrection était essentiellement absente dans les modèles purement pré-entraînés. Elle est due au fait que l'objectif de la LR incite explicitement à obtenir des résultats corrects, ce qui oblige le modèle à développer des contrôles et des équilibres internes. La formation standard basée sur la vraisemblance permet aux modèles de reproduire des schémas de comportement intelligents, mais ne les prépare pas à des scénarios nouveaux ou inattendus. En revanche, les modèles formés avec le RL général développent des capacités de correction d'erreurs dès le départ. Un modèle adapté au RL apprend ce qu'il faut faire lorsqu'il ne le sait pas, et il peut essayer une approche différente ou réévaluer soigneusement les étapes précédentes. Les modèles les plus récents reconnaissent lorsqu'ils se trompent et ne se contentent pas d'halluciner une meilleure supposition : L'IA IMO d'OpenAI semble avoir fait des progrès substantiels dans ce domaine.
Le RL rend donc les modèles robustes et orientés vers un objectif. Au lieu de régurgiter passivement les données d'apprentissage, le modèle tente activement de maximiser la récompense, ce qui signifie généralement résoudre le problème en question. En codage, la récompense peut être la réussite de tous les tests unitaires; en mathématiques, l'obtention de la bonne réponse numérique ; en dialogue, la satisfaction de l'utilisateur ou le respect des instructions. Chaque fois que nous disposons d'une mesure de succès bien définie, nous pouvons utiliser la NR pour pousser le modèle à l'optimiser. Cela a conduit à ce que l'on pourrait appeler les grands modèles de raisonnement (LRM), des modèles de langage conçus pour effectuer des raisonnements à plusieurs étapes de manière fiable. Ces modèles suivent des chaînes de raisonnement plus longues, reviennent sur les erreurs et décomposent les problèmes en sous-étapes grâce au RL ou à des techniques apparentées.
Il convient de dissiper un malentendu : certains pensent que le RL sur les modèles linguistiques ne fait que les affiner légèrement. En réalité, une formation prolongée et généraliste en NR peut débloquer des stratégies de solution entièrement nouvelles, absentes du modèle de base. Le modèle mathématique IMO Gold d'OpenAI est le même que le modèle de codage IOI Gold.. OpenAI n'a pas formé de modèle spécifique pour l'IOI - "Le raisonnement généralise !"
Les chercheurs ont constaté qu'en optimisant suffisamment le langage logique sur diverses tâches de raisonnement, les modèles peuvent découvrir des méthodes de résolution de problèmes qui ne figuraient pas dans leurs expériences de pré-entraînement. L'article du ProRL observe que "le RL peut découvrir de nouvelles voies de solution entièrement absentes des modèles de base lorsqu'il dispose d'un temps d'entraînement suffisant et de nouvelles tâches de raisonnement". Il est intéressant de noter que ce sont les modèles de base les plus faibles qui ont le plus bénéficié de ProRL, probablement parce qu'ils avaient plus de possibilités d'action et qu'ils ont été contraints d'innover dans de nouveaux schémas de raisonnement pour obtenir des récompenses. Cela suggère que le RL ne se contente pas d'affiner les capacités connues, mais qu'il repousse les limites de ce que les modèles peuvent faire.
Une suite de tests appelée Reasoning Gym, qui fournit des problèmes logiques générés de manière procédurale avec des solutions vérifiables, a montré un écart de performance de 22% entre le meilleur modèle entraîné par RL et le meilleur modèle non RL - même lorsque le modèle non RL était plus grand! Les petits modèles qui avaient été soumis à un processus de raisonnement intensif ont surpassé les grands modèles qui ne l'avaient pas été, ce qui démontre que "le processus de raisonnement débloque des capacités qualitativement différentes" et permet d'acquérir des compétences largement applicables en matière de résolution de problèmes, plutôt que des astuces étroites.
Ces développements mettent en évidence un thème central : l'optimisation de la trajectoire par rapport à la prédiction statique. Un modèle génératif tente de prédire un résultat, tandis qu'un agent de raisonnement tente d'obtenir un résultat. Le premier risque de trébucher si le problème nécessite plusieurs étapes, alors que le second élabore une stratégie à travers ces étapes. Avec le RL, le modèle apprend à considérer chaque jeton ou action comme faisant partie d'une trajectoire au service d'un objectif. Sa formation lui apprend à naviguer dans des espaces d'état, et pas seulement à produire des corrélations locales. Ce changement fondamental - de l'apprentissage de correspondances statiques entre les entrées et les sorties à l'apprentissage de politiques dynamiques - est à la base du succès de Reasoning AI.
La combinaison de SSL à grande échelle (pour les connaissances générales) et de RL (pour le raffinement centré sur les objectifs) produit des systèmes d'IA qui généralisent mieux et transfèrent la capacité de raisonnement à travers les domaines. Un modèle linguistique auquel on apprend, par le biais de la LR, à "réfléchir sérieusement" aux problèmes mathématiques obtient également de bien meilleurs résultats aux tests juridiques, biologiques et économiques. Une fois que le modèle a appris à allouer des ressources informatiques au raisonnement dans un domaine, il exploite cette compétence dans d'autres domaines. Il ouvre une nouvelle courbe d'échelle au-delà de la taille du modèle ou de l'ensemble de données. Nous pouvons améliorer les performances de raisonnement en nous entraînant sur un plus grand nombre de tâches de raisonnement ou en intégrant des signaux d'objectifs plus sophistiqués.
Optimisation de la trajectoire ou prédiction d'un seul coup
Pour cristalliser le contraste : l'IA générative était principalement axée sur la prédiction, tandis que l'IA raisonnante est axée sur l'optimisation (à la fois lors de l'apprentissage et de l'inférence). Un modèle d'IA générative tel que GPT-3 génère du texte en prédisant l'élément suivant en fonction de sa formation. Il n'a pas d'autre but que d'imiter la distribution de texte qu'il a vue. Il minimise la perte de prédiction du prochain jeton. Un modèle d'IA de raisonnement, en revanche, peut être explicitement formé pour maximiser une récompense telle que "problème résolu correctement", qui dépend de la cohérence et de l'exactitude d'une séquence entière de jetons. Il s'agit d'un objectif non différentiable et peu dense qui ne peut pas être optimisé par l'apprentissage supervisé standard ; ilfaut recourir à l'apprentissage aléatoire.
Cela conduit à un comportement fondamentalement différent. Un prédicteur statique se contente souvent d'une réponse plausible qui semble correcte au niveau local, même si elle est erronée au niveau mondial. Un agent optimisant la trajectoire est incité à vérifier et à valider chaque étape, car une seule étape erronée peut réduire à néant la récompense. Il fait preuve de persévérance et d'adaptabilité. Dans la résolution de problèmes mathématiques, un LLM traditionnel peut donner une réponse rapide qui semble correspondre à peu près à la bonne grandeur, alors qu'un modèle de raisonnement entraîné par RL montrera plus probablement le travail, remarquera si les résultats intermédiaires ne sont pas corrects et essaiera à nouveau jusqu'à ce qu'il obtienne la réponse exacte. Il traite la tâche comme un mini-problème d'optimisation : trouver une séquence d'étapes de raisonnement produisant la bonne réponse finale. Ce faisant, il effectue une recherche - guidée par les connaissances acquises au cours de la formation - dans l'espace des solutions possibles.
Cette orientation vers "l'accomplissement de la tâche" plutôt que vers "la prédiction du mot suivant" rend l'IA de raisonnement performante pour les tâches complexes. Cependant, elle exige que nous définissions clairement la tâche et ses critères de réussite. En termes d'apprentissage par renforcement, nous avons besoin d'une bonne fonction de récompense. Si vous pouvez préciser ce qui constitue la réussite d'une tâche complexe, une IA peut de plus en plus apprendre à y parvenir, moyennant un entraînement et un calcul d'inférence suffisants. Donnez au modèle les interfaces/outils appropriés et concevez un signal de récompense adéquat, et l'IA pourra découvrir le reste par essais et erreurs. Il ne s'agit pas de problèmes triviaux, mais il est probable qu'ils puissent être résolus pour de nombreuses tâches importantes. Ce cadrage s'avère utile lorsque l'on envisage d'appliquer l'IA de raisonnement à des domaines réels, comme nous l'explorerons dans le contexte des flux de travail d'entreprise.
Percées empiriques : Raisonner les performances de référence de l'IA
Les prouesses de l'IA de raisonnement apparaissent clairement dans les modèles les plus récents. Prenons l'exemple du GPT-5 récemment mis sur le marché.
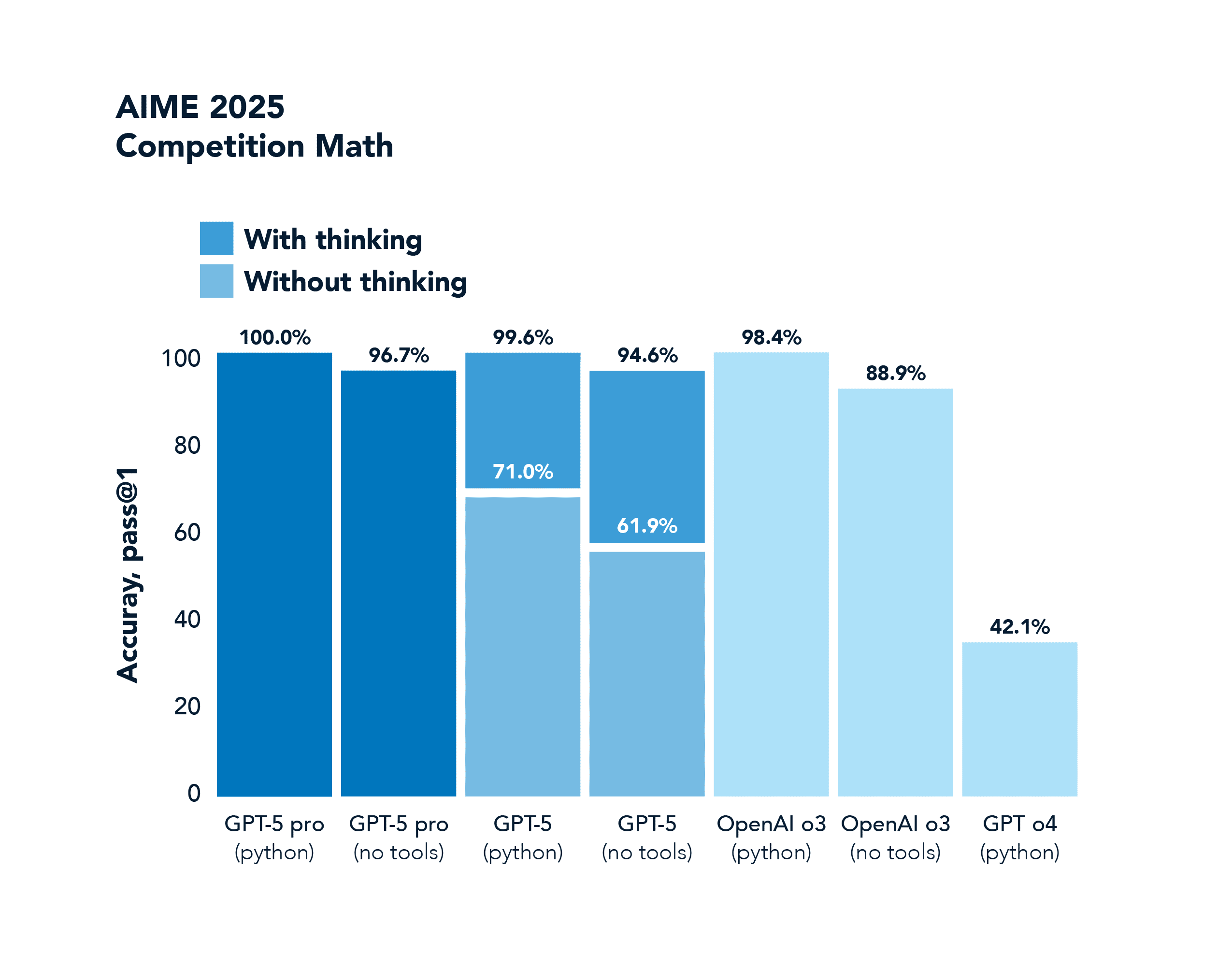
L'AIME est un concours de mathématiques. GPT-4o obtient un score de 42,1%, et GPT-5 sature complètement ce point de référence avec un score de 100,0%. score.
SWE-Bench est un benchmark de codage du monde réel. Le GPT-4o obtient un score de 30,8%, tandis que le GPT-5 avec réflexion obtient un score de 74,9%.
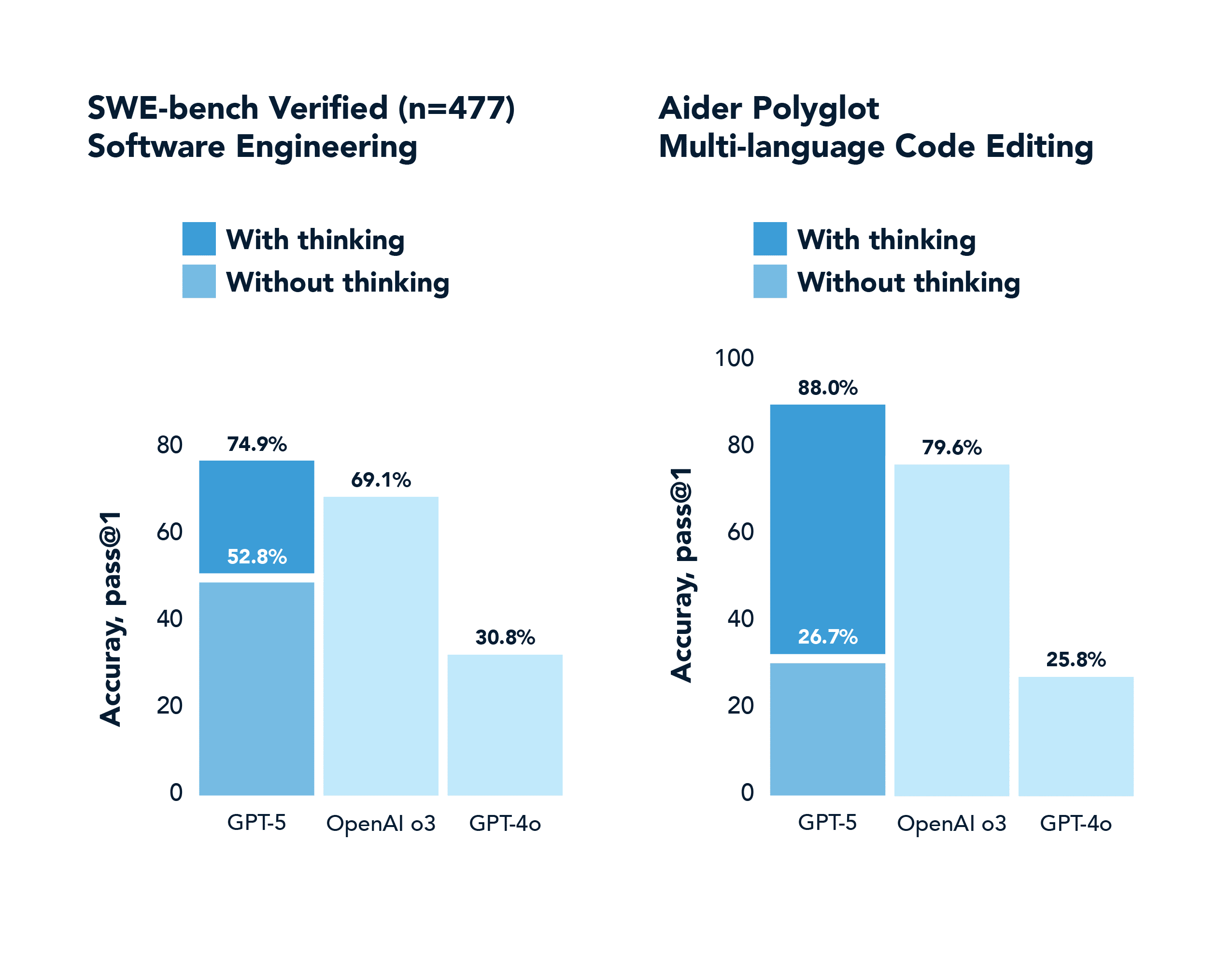
L'axe des ordonnées de ces graphiques mérite d'être souligné, car il reflète un phénomène plus général connu sous le nom de " pass@k performance shifts". Pour les modèles génératifs effectuant des tâches difficiles, il y avait traditionnellement un écart important entre pass@1 (produire une solution correcte au premier essai) et pass@100 (produire au moins une solution correcte sur 100 essais). Les modèles de raisonnement ont considérablement comblé ce fossé en internalisant de meilleures politiques de résolution des problèmes. Ils réussissent beaucoup plus souvent du premier coup, grâce à la chaîne de pensée et à la formation en NR. Et s'ils bénéficient de plusieurs tentatives, ils les utilisent intelligemment.
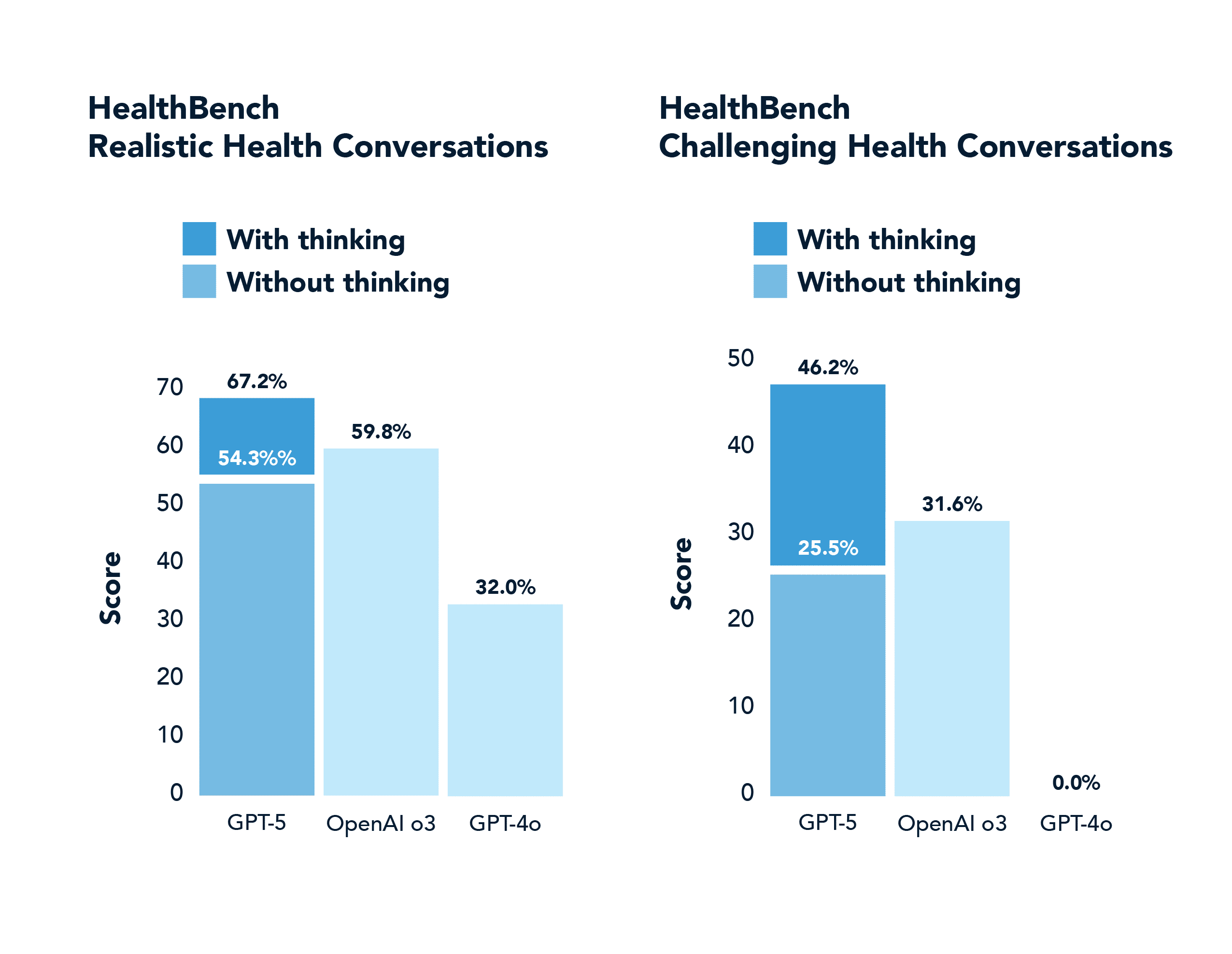
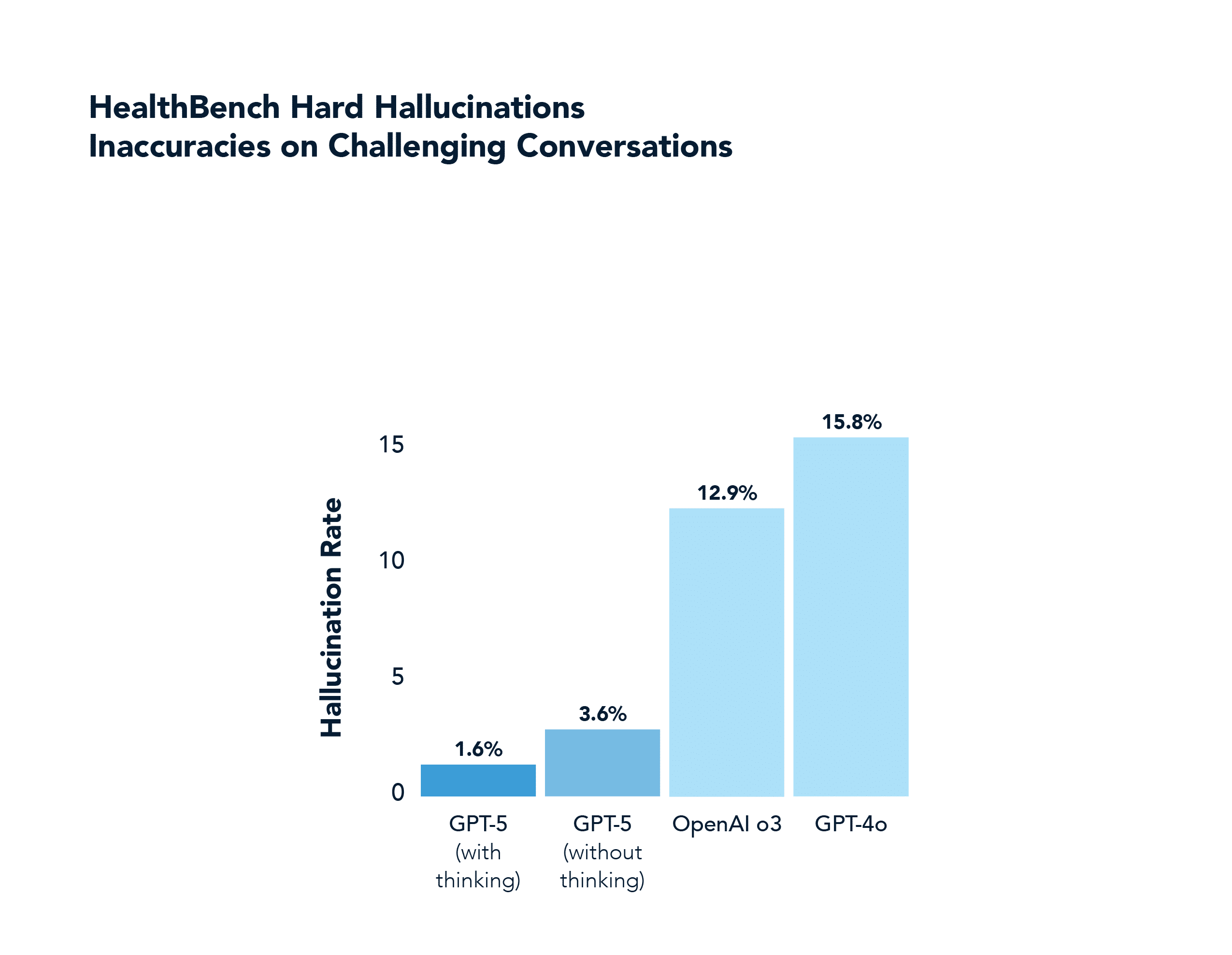
Dans un domaine non mathématique ou de codage comme la santé, le GPT-5 obtient également des résultats nettement supérieurs à ceux du GPT-4o, notamment en répondant correctement à près de la moitié des problèmes "difficiles" que le GPT-4o a réussi à résoudre 0,0% fois (et avec beaucoup moins d'hallucinations). Ce domaine a été mis en évidence dans le flux de lancement du GPT-5.
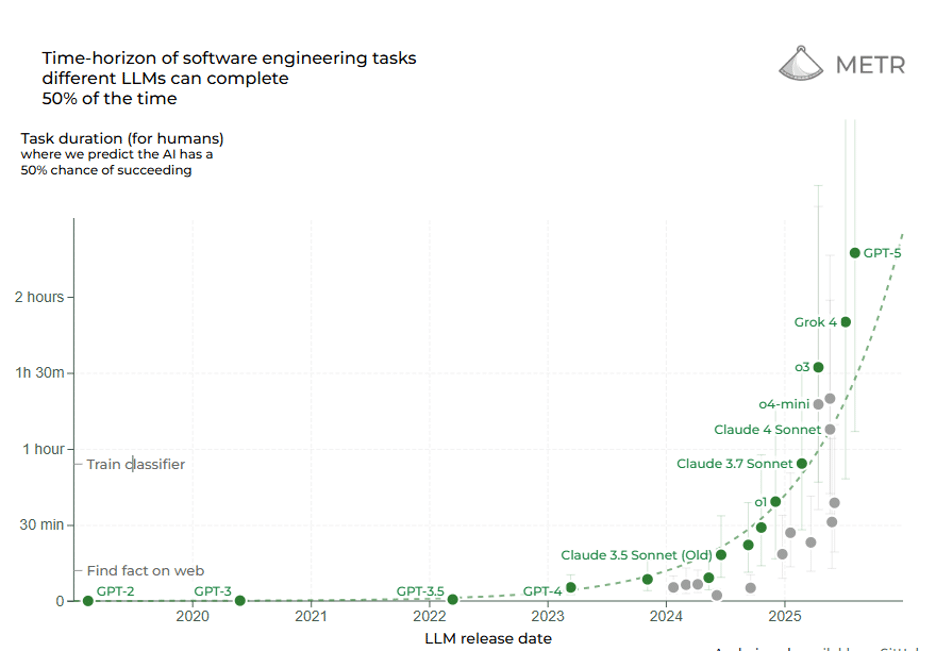
L'horizon temporel est un autre moyen d'évaluer la frontière de l'IA de raisonnement: la durée d'une tâche (mesurée en temps humain pour l'accomplir) qu'une IA peut gérer de manière autonome. Une étude récente intitulée Measuring Task Horizon (METR) a révélé que depuis 2019, la durée des tâches que les systèmes d'IA peuvent effectuer de manière fiable a augmenté de manière exponentielle, avec un temps de doublement d'environ 7 mois. En 2019, l'IA la plus performante pourrait traiter des tâches prenant quelques secondes à un humain ; en 2023, elle traiterait des tâches prenant plusieurs minutes ; aujourd'hui, en 2025, nous voyons des tâches de l'ordre de plusieurs heures exécutées par l'IA. Les critères de référence impliquant l'écriture d'un code ou la conduite d'une recherche (auxquels les humains consacrent des heures) sont désormais à portée de main. En 2025, les modèles de raisonnement frontalier atteindront 50% pour des tâches qui prendraient plus de 2 heures à une personne. Selon le METR, le modèle de raisonnement initial d'OpenAI o1 (publié en décembre 2024) pouvait accomplir une tâche de 39 minutes 55,9% du temps ; le GPT-5 récemment publié peut accomplir une tâche de 2 heures et 17 minutes 69,6% du temps ( !). La ligne de tendance suggère qu'au cours des cinq prochaines années, les horizons temporels de l'IA pourraient s'étendre à des jours ou des semaines, ce qui signifie qu'une IA pourrait potentiellement mener à bien un projet couvrant de nombreux jours ouvrables d'efforts. L'IA de raisonnement étend non seulement la précision, mais aussi le champ d'application de l'autonomie.
Les données disponibles indiquent clairement que nous sommes entrés dans un nouveau régime de capacités d'IA. La génération précédente de modèles suivait des courbes d'échelle lisses - des améliorations prévisibles avec davantage de paramètres ou de données, mais dans le même mode opérationnel. La nouvelle génération - les agents d'IA raisonnante avec RL et recherche en temps réel - introduit des discontinuités dans ces courbes. Ils atteignent des niveaux de performance pour certaines tâches qui étaient impossibles avec l'ancienne approche.
L'IA de raisonnement met de nouvelles tâches complexes à la portée de tous
L'aspect le plus intéressant de l'IA raisonnante est l'éventail des tâches du monde réel qu'elle peut aborder et qui étaient auparavant beaucoup trop complexes et nuancées pour les machines. Les processus d'entreprise impliquent souvent de longues séquences de décisions, beaucoup d'informations non structurées et la nécessité de contrôler les erreurs - exactement là où Reasoning AI se distingue. Les secteurs tels que la finance, le droit, la médecine et l'ingénierie regorgent d'exemples de ce type : préparations fiscales fastidieuses, rédaction de contrats juridiques, analyses cliniques, dépannage de conceptions techniques. Celles-ci nécessitent souvent de 2 à 10 heures de travail cognitif humain par instance, avec des allers-retours et des vérifications importants.
Jusqu'à récemment, les tentatives d'automatisation à l'aide de l'IA ont échoué car les modèles conventionnels s'égaraient inévitablement à un moment ou à un autre et n'avaient aucun moyen de s'en remettre. Mais avec l'avènement d'agents d'intelligence artificielle guidés par des objectifs et s'auto-corrigeant, bon nombre de ces tâches "non automatisables" sont en train d'entrer dans le champ d'application.
Étude de cas : Automatiser la préparation des impôts grâce à l'IA raisonnée
Considérez le processus de préparation d'une déclaration d'impôts complexe pour une petite entreprise ou un particulier avec de multiples sources de revenus et de déductions(ce cas d'utilisation spécifique a été discuté dans le podcast de Dwarkesh avec Sholto Douglas et Trenton Bricken d'Anthropic). Cette tâche peut facilement prendre de 4 à 6 heures du temps d'un comptable. Il s'agit de collecter de nombreux documents (W2, 1099, reçus), d'interpréter les règles et codes fiscaux, d'effectuer des calculs étape par étape pour différents formulaires, de vérifier la cohérence de ces formulaires par recoupement et d'itérer si des erreurs sont trouvées ou si de nouvelles informations sont révélées. Les règles fiscales changent chaque année et comportent de nombreux cas particuliers, ce qui nécessite des connaissances générales et une adaptation. C'est l'exemple même d'un processus très complexe et lourd de conséquences.
À l'ère de l'IA analytique, on aurait pu construire Logiciel avec un organigramme rigide ou un ensemble de formules pour faciliter le calcul des impôts, mais il n'aurait rien pu faire d'inattendu ; toute déviation nécessitait une intervention humaine. À l'ère de l'IA générative, vous pourriez utiliser un modèle de langage pour répondre à des questions fiscales spécifiques ou remplir un seul formulaire à partir de données, mais il ne pourrait pas gérer l'ensemble du processus multi-formulaire de manière fiable, ni savoir comment se revérifier.
C'est là qu'intervient l'IA raisonnée. Un agent de raisonnement pour la préparation des impôts aborderait le problème de la même manière qu'un fiscaliste humain, mais avec des capacités de calcul accrues :
Comprendre l'objectif et les contraintes : L'IA reçoit l'objectif (préparer une déclaration d'impôts complète et exacte pour l'année X pour le client Y) et l'accès aux ressources : les documents du client (analysés par OCR), les API de Logiciel fiscal ou les modèles de formulaires, et une base de connaissances sur les lois fiscales. Surtout, il dispose d'un moyen de vérifier l'exactitude des données. Il peut interroger une API de calcul officielle de l'IRS ou utiliser une simulation connue pour vérifier si la déclaration est susceptible de passer les contrôles d'audit (essentiellement un signal de récompense pour une déclaration correcte).
Planification et décomposition : L'agent décompose la tâche en sous-tâches : (1) analyser et extraire tous les éléments de revenu des documents, (2) déterminer les formulaires fiscaux requis, (3) remplir les champs requis étape par étape pour chaque formulaire, (4) vérifier les totaux et les références entre les formulaires, (5) examiner les optimisations ou les erreurs potentielles, (6) produire la déclaration finale pour l'archivage.
Remplissage et vérification itératifs : Pour chaque sous-tâche, l'IA invoque les outils appropriés. Il peut utiliser la chaîne de réflexion pour interpréter un formulaire 1099-B et en extraire les chiffres pertinents, en effectuant des calculs pour les plus-values. Il reporte ces chiffres sur l'annexe D, puis s'assure que le résultat de l'annexe D est correctement reporté sur le formulaire principal 1040. À chaque étape, il peut faire une pause et vérifier : le nombre figurant à la ligne 7 de l'annexe D est-il égal au total figurant sur le formulaire 1099-B ? Si ce n'est pas le cas, il détecte une erreur et la corrige. C'est là que la récupération des erreurs s'avère essentielle - un agent IA de raisonnement serait formé à toujours recouper les totaux des formulaires et à itérer jusqu'à ce qu'ils soient réconciliés. Contrairement à un modèle génératif qui pourrait produire des chiffres incohérents, un agent de raisonnement dispose d'une boucle interne : si les vérifications échouent, il faut corriger et répéter.
Généralisation et adaptation : Supposons que le client se trouve dans une situation fiscale inhabituelle (revenus en crypto-monnaie ou déduction obscure). Un programme standard peut se bloquer ou un modèle de base peut avoir des hallucinations. Mais notre IA de raisonnement, dotée de capacités de recherche, peut dynamiquement extraire le code fiscal ou le précédent pertinent et l'intégrer dans sa chaîne de réflexion. Parce qu'il fonctionne sur la base de principes (satisfaction des objectifs) plutôt que par simple mimétisme, il peut gérer des scénarios inédits avec plus d'habileté. Il déterminera comment traiter les nouvelles données en vue de maximiser l'exactitude et la conformité.
Raisonnement sur les sous-buts et attribution de crédits : L'agent définit des sous-buts internes tels que "calculer le revenu total", "calculer les déductions totales", "calculer l'impôt dû", chacun d'entre eux devant être correct pour que la déclaration globale soit correcte. Si la vérification finale échoue, il est possible d'identifier le sous-but qui a probablement fait l'objet d'une erreur et de le réexaminer spécifiquement. Ce retour en arrière ciblé n'est possible que parce que l'IA ne génère pas l'intégralité du retour en une seule fois. Il s'agit d'un raisonnement à travers un processus structuré.
Vérification finale : L'IA n'arrête et ne soumet la déclaration que lorsque tous les tests de validation sont réussis : La déclaration est cohérente sur le plan interne et peut même réussir un test de simulation. Cela permet d'obtenir un signal de récompense robuste : Récompense = 1 si le retour est valide et cohérent, sinon 0. Lors de l'exécution, l'agent utilise ces listes de contrôle pour s'assurer qu'il respecte les critères de réussite.
La préparation des impôts peut être abordée comme un problème de raisonnement à long terme avec des sous-objectifs vérifiables, ce qui permet à l'IA de raisonner. Nous avions besoin d'une combinaison de composants qui existent aujourd'hui : l'OCR et l'extraction d'informations, un modèle de connaissance pré-entraîné, une politique de RL superposée et une recherche en temps réel.
Une telle IA réduirait considérablement le temps et le coût de la préparation des impôts. Il pourrait fonctionner sans relâche, traiter en quelques minutes ce qui prend des heures aux experts, en exploitant le calcul par force brute lorsque cela est nécessaire. Et surtout, il ne se briserait pas ou n'abandonnerait pas facilement - si un chiffre ne s'additionne pas, il s'en aperçoit et le corrige. Cela représente un changement radical par rapport aux logiciels précédents.
Raisonner l'IA dans des domaines difficiles à vérifier : Autres études de cas
Certains flux de travail sont difficiles non pas parce que la chaîne de raisonnement est longue (comme dans le cas des impôts), mais parce que la vérité de terrain elle-même est ambiguë, incomplète ou contestable. Parmi les exemples classiques, citons le contrôle de la conformité, l'interprétation des lois, la synthèse des recherches et la planification stratégique. Les modes de défaillance sont ici plus subtils : Le résultat peut sembler plausible mais contenir des contradictions cachées ou des contraintes négligées.
Les chercheurs en LR ont commencé à intégrer des modules de vérification dans la fonction de récompense elle-même. Dans Trust, But Verify, Liu et. al forment des modèles de langage pour proposer des réponses et critiquent ensuite leur propre chaîne de pensée ; la récompense n'est accordée que lorsque le critique et un vérificateur externe sont d'accord. Sur les questions politiques ouvertes, pour lesquelles il n'existe pas d'étiquette unique, l'agent d'auto-vérification a réduit les erreurs hallucinatoires de 38% par rapport aux lignes de base RLHF (apprentissage par renforcement à partir du retour d'information humain).
Ces résultats suggèrent une voie à suivre : Pour toute tâche difficile à vérifier, concevez des contrôles partiels indiscutables (par exemple, cohérence logique, exactitude des citations légales, équilibre numérique). L'apprentissage par renforcement apprend alors au modèle à faire passer son raisonnement par ces points de contrôle. Au fil du temps, l'agent intériorise des heuristiques qui lui permettent de reconnaître qu'il se trouve sur un terrain incertain et déclenche la collectede preuves supplémentaires - tout comme un auditeur chevronné demande une pièce justificative lorsque quelque chose ne lui semble pas normal. Les travaux difficiles à vérifier deviennent donc plus faciles à réaliser lorsque l'IA peut prouver chaque étape localement, même si le résultat global est subjectif.
La préparation des impôts n'est qu'un exemple parmi d'autres. Des analyses similaires s'appliquent à de nombreuses autres tâches complexes :
Audit financier : Passer en revue des milliers de transactions pour trouver des divergences nécessite de raisonner sur chacune d'entre elles et d'agréger des preuves. Une IA de raisonnement pourrait planifier un audit, le mener en examinant les dossiers, signaler les anomalies et adapter sa stratégie si des schémas inattendus apparaissent - pour finalement garantir la concordance des comptes.
Révision de contrats juridiques : Comprendre des contrats complexes, les comparer aux normes de l'entreprise et proposer des révisions implique une lecture attentive, un raisonnement logique sur les clauses et des suggestions créatives. Un modèle de raisonnement pourrait examiner séquentiellement chaque clause, se référer à une base de connaissances de phrases à risque et affiner de manière itérative un projet de contrat.
Diagnostic médical et planification du traitement : Compte tenu des antécédents et des symptômes d'un patient, un agent raisonneur pourrait générer des diagnostics possibles, recueillir davantage d'informations, puis réduire le nombre de diagnostics et proposer un traitement. Ce processus de raisonnement naturellement itératif pourrait être amélioré grâce à la logique de résolution basée sur les résultats et la planification d'interactions en plusieurs étapes.
Dépannage de l'assistance à la clientèle : Une IA capable de résoudre des problèmes techniques complexes en recueillant systématiquement des informations, en formulant des hypothèses, en testant des solutions et en assurant un suivi peut faire face à des surprises que les flux scénarisés ne peuvent pas gérer. Formé à l'objectif de résoudre les problèmes avec une grande satisfaction du client, il sera persévérant et minutieux.
Du " LLM Wrapper"au" RL Sculptor" : La personnalisation du raisonnement crée de véritables fossés concurrentiels
Il y a également une implication stratégique. Les entreprises qui identifient les tâches complexes de valeur et développent des solutions d'IA de raisonnement sur mesure peuvent acquérir d'importantes positions concurrentielles. Le succès dépend souvent des bonnes définitions des récompenses et des boucles d'entraînement curatives, ainsi que de la tolérance à des calculs d'inférence lourds. L'époque des enveloppes LLM est révolue. Vous ne pouvez pas vous contenter d'utiliser des API de base. Vous devez les construire, éventuellement en collectant des données ou des simulateurs pour vous entraîner. Si une société de logiciels comptables crée un environnement RL propriétaire pour les déclarations fiscales et y entraîne une IA de raisonnement spécialisée, il s'agit d'un investissement substantiel qu'il n'est pas facile de reproduire. Le résultat final serait une IA qui ne se contente pas d'automatiser les impôts, mais qui s'améliore continuellement. Une telle IA pourrait être proposée en tant que service premium à forte intensité d'inférence, dans le cadre duquel les impôts sont calculés pendant la nuit par une IA en nuage utilisant 100 fois plus de calcul par tâche que les modèles typiques, garantissant que chaque déduction est optimisée et que chaque chiffre est vérifié deux fois. Le coût par requête pourrait être plus élevé(le score élevé de l'ARC de o3 high coûte plus de 200 $ par tâche en calcul), mais la valeur apportée pourrait le justifier. Dans de nombreuses tâches d'entreprise à fort enjeu, la précision et la minutie valent bien plus que les cycles de calcul. Ces entreprises auront besoin de plus de capitaux au début, mais elles établiront des fossés dans les performances, ce qui n'est pas courant pour les entreprises de l'ère de la GenAI.
OpenAI propose des modes "haute efficacité" et "faible efficacité", ce dernier utilisant beaucoup plus de calcul pour atteindre des taux de réussite plus élevés. Ils ont introduit des modèles de tarification pour en tenir compte. Une organisation adoptant l'IA de raisonnement pourrait également proposer des niveaux de service : un mode rapide qui fonctionne généralement, et un "mode approfondi" dans lequel l'IA dispose de plus de temps et de calculs pour maximiser le succès. Ces cycles supplémentaires pourraient être consacrés à un raisonnement plus approfondi ou à l'exploration de nouvelles possibilités. Quoi qu'il en soit, cela peut être un argument de vente : "Notre IA fera les choses correctement, même si elle doit réfléchir plus longtemps - et nous avons validé ce que signifie "correctement" pour votre entreprise".
Cela suggère que les premiers à déployer l'IA de raisonnement dans des flux de travail complexes bénéficieront d'avantages considérables. Ils accumuleront des données et un retour d'information spécifiques à la tâche (puisque chaque déploiement produit des journaux sur la manière dont l'IA a raisonné et sur ses difficultés, ce qui permet d'affiner le système) ; ils amélioreront leurs mesures de récompense au fil du temps (en remarquant si la récompense manque quelque chose et en l'ajustant) ; et ils développeront une expertise en matière d'intégration - en sachant comment permettre à l'agent d'IA d'interagir avec les logiciels existants ou les configurations humaines en boucle de manière efficace. Les retardataires auront une pente plus raide à gravir.
Conclusion : Le raisonnement sur l'IA exige un changement d'état d'esprit
Dans l'évolution de l'IA, nous assistons à un changement aussi fondamental que l'introduction de l'apprentissage profond lui-même. L'IA de raisonnement annonce un paradigme dans lequel les systèmes d'IA ne sont pas des prédicteurs statiques mais des résolveurs de problèmes actifs qui peuvent planifier, expérimenter et s'auto-corriger dans la poursuite d'objectifs. Ce nouveau paradigme est rendu possible par la combinaison des forces des modèles de fondation auto-supervisés (vastes connaissances et reconnaissance des formes) avec l'apprentissage par renforcement (optimisation des objectifs et retour d'information) et l'adoption d'un calcul intensif du temps d'inférence (pensée itérative). Il en résulte une IA beaucoup plus généralisable et fiable pour les tâches complexes que ses prédécesseurs.
Alors que l'IA analytique traitait des données bien définies et que l'IA générative maîtrisait l'expression fluide, l'IA de raisonnement s'attaque aux défis désordonnés et de longue haleine du monde réel. Il se rapproche des compétences humaines dans les domaines nécessitant une "intelligence fluide", c'est-à-dire l'efficacité de l'acquisition des compétences et la capacité d'adaptation que François Chollet a mises en évidence dans sa définition de l'intelligence. La preuve en est que les performances ont augmenté dans tous les domaines, des modèles comme o3 marquant une "véritable avancée" par rapport aux limitations antérieures et GPT-5 résolvant des questions de santé entendues que des modèles non raisonnés comme 4o résolvent 0,0% du temps.
Mais ce n'est probablement qu'un début. Au fur et à mesure que ces techniques évolueront, nous verrons les IA de raisonnement améliorer l'utilisation des outils et exploiter les systèmes de mémoire à long terme pour conserver les connaissances d'une session à l'autre. Chaque extension permettra d'élargir encore leur champ d'action. Les défis mentionnés - donner aux modèles la bonne fidélité de l'interaction avec le monde et les bonnes mesures de réussite - sont activement abordés. Avec les robots, les chercheurs appliquent les mêmes architectures de raisonnement pour leur permettre de planifier des actions physiques. Dans Logiciel, les agents sont conçus pour utiliser des ordinateurs afin d'accomplir des tâches, transformant le monde lui-même en "environnement" pour leur formation à la RL. Bientôt, il sera peut-être normal d'avoir des collègues IA qui prennent en charge des projets de plusieurs jours, coordonnent avec les humains et conduisent de manière autonome vers les objectifs, en apprenant et en s'adaptant au fur et à mesure. Le travail humain qui comporte une longue série de nouvelles tâches de distribution hors formation qui ont toujours nécessité un raisonnement humain peut désormais être abordé grâce à l'IA raisonnante.
Pour les entreprises et la société, l'émergence d'une IA capable de raisonner représente à la fois une opportunité et une responsabilité. L'opportunité réside dans le déblocage d'une immense productivité et dans la résolution de problèmes jusqu'ici trop complexes ou trop coûteux. La recherche scientifique approfondie, les optimisations massives de la conception technique et les plans d'éducation personnalisés pourraient tous être accélérés par des IA qui examinent les données et les possibilités beaucoup plus rapidement que nous, tout en se corrigeant elles-mêmes pour rester sur la bonne voie. La responsabilité vient du fait qu'un raisonnement plus puissant signifie également un raisonnement erroné plus puissant si les objectifs sont mal spécifiés. Nous devons veiller à ce que les signaux de récompense que nous émettons correspondent aux résultats que nous souhaitons obtenir, faute de quoi un super-raisonneur pourrait trouver des moyens astucieux de déjouer le système (le problème classique du "reward hacking"). La bonne nouvelle, c'est que les outils qui permettent à l'IA de mieux raisonner peuvent aussi la rendre plus transparente. En leur demandant d'externaliser les chaînes de pensée, nous obtenons une fenêtre sur leur processus de décision, ce qui peut faciliter les audits et l'alignement. Nous avons vu que l'intégration de considérations éthiques ou de sécurité dans la chaîne de pensée peut donner lieu à des modèles à la fois plus intelligents et plus sûrs.
En résumé, nous sommes à l'aube de l'ère de l'IA raisonnante. Il s'agit d'une nouvelle frontière où les machines ne se contentent pas de générer des réponses, mais s'efforcent de trouver des solutions. Ce changement de paradigme redéfinira les limites des tâches que nous considérons comme automatisables. Les années à venir seront consacrées à la mise à l'échelle de ces boucles de rétroaction, à leur élargissement à d'autres tâches et à l'intégration de ces agents de raisonnement dans le tissu de notre façon de travailler et de résoudre les problèmes. Ceux qui comprennent et adoptent ce changement - en investissant dans les données nécessaires, la conception des récompenses et l'informatique - seront à l'avant-garde de la prochaine vague d'innovation. Il est possible que nous approchions des limites des approches traditionnelles de mise à l'échelle, mais nous sommes maintenant en train d'escalader une nouvelle courbe alimentée par l'IA qui apprend à penser. La remontée de cette courbe ne fait que commencer, et elle promet de transformer ce que nous imaginons que l'IA peut faire.
Les informations contenues dans le présent document reposent uniquement sur les opinions de Brandon Gleklen, et rien ne doit être interprété comme un conseil d'Investissements. Ce document est fourni à titre informatif uniquement et ne saurait en aucun cas constituer un conseil juridique, fiscal ou en matière d'investissement, ni une offre de vente ou une sollicitation d'offre d'achat d'une participation dans un fonds ou un véhicule d'investissement géré par Battery Ventures ou toute autre entité d'Battery. Les opinions exprimées ici sont celles des auteurs et ne reflètent pas nécessairement celles de l'éditeur.
Les informations ci-dessus peuvent contenir des projections ou d'autres déclarations prospectives concernant des événements ou des attentes futurs. Les prévisions, opinions et autres informations présentées dans cette publication sont susceptibles d'être modifiées en permanence et sans préavis d'aucune sorte, et peuvent ne plus être valables après la date indiquée. Battery Ventures n'assume aucune obligation et ne s'engage pas à mettre à jour les déclarations prévisionnelles.
*Dénote une entreprise de Battery Portefeuille. Pour une liste complète de tous les investissements et sorties de Battery, veuillez cliquer sur ici.

Un bulletin d'information mensuel pour partager de nouvelles idées, des aperçus et des introductions pour aider les entrepreneurs à développer leurs entreprises.